In my first NuoDB blog , I explained how to deploy the NuoDB database in a Kubernetes environment using OpenEBS storage. In this post we will test the OLTP performance capabilities of NuoDB and the Continuous Availability. for the SQL workload generator we will use YCSB in a pod,the Yahoo Cloud Serving Benchmark tool.
What is YCSB?
Yahoo! Cloud Serving Benchmark (YCSB) is a framework for benchmarking database management systems.
NuoDB packaged YCSB in a convenient Docker form to permit benchmarking container-native databases such as NuoDB.
Prerequisites
Before you get started, you’ll need to have these things:
- A kubernetes cluster (1 master and 3 workers nodes) on linux instance
- Configuration of each node : 16 vCPUs - 32GB RAM - 120 GB of storage
- HELM > 3.0.x
- OpenEBS 1.4.0
- package tuned installed
- NuoDB 4.x installed
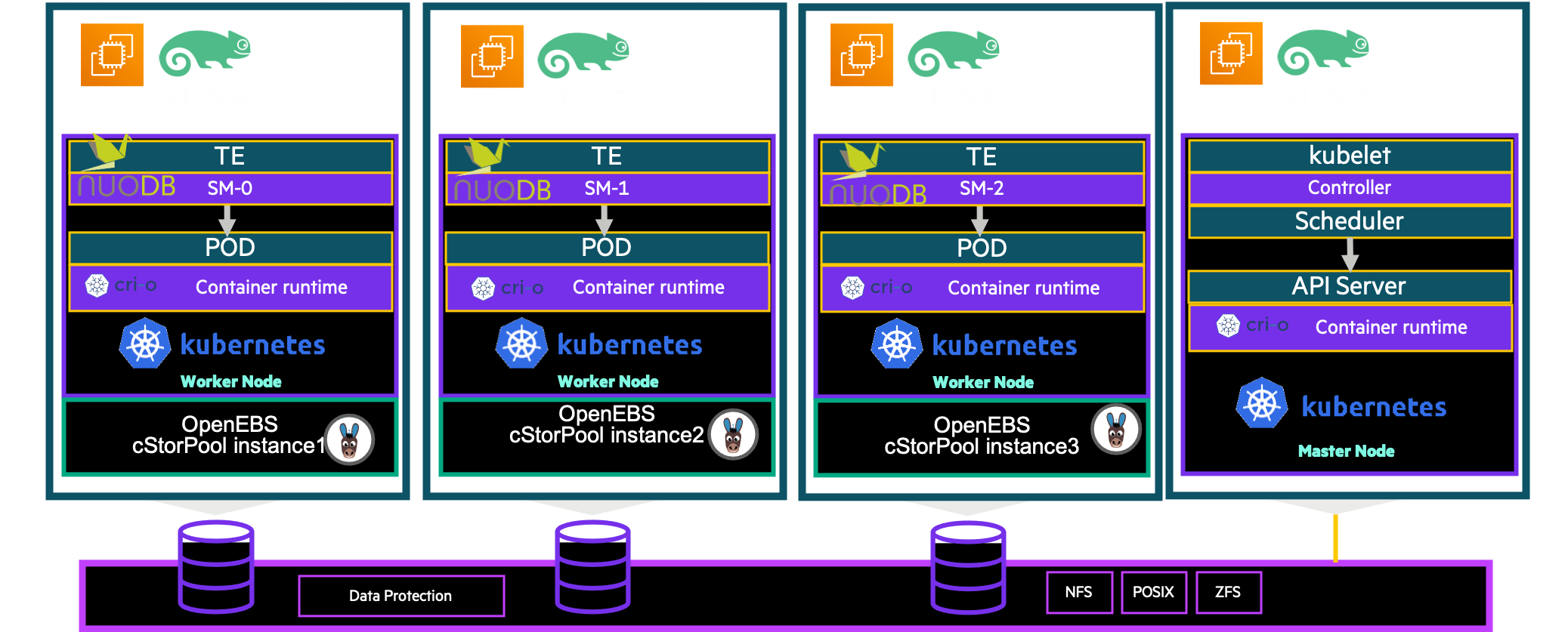
Architecture
I will use the following architecture :
Install and start the YCSB SQL workload benchmark tool
By default, the YCSB container will create 10 connections to your database and each connection will run 10K SQL statements with a mix of 95% reads and 5% updates, then disconnect, and start a new connection, and so on.
Deploying the YCSB Pod :
$> kubectl -n nuodb apply -f https://raw.githubusercontent.com/colussim/NuoDB/main/Deployer-YSCB/nuodb-ycsb-0.yaml
replicationcontroller/ycsb-load created
$>Verify the pods are running :
$> kubectl get pods -n nuodb
NAME READY STATUS RESTARTS AGE
admin-nuodb-cluster0-0 3/3 Running 0 10d
insights-grafana-57ff765c78-fsc2w 2/2 Running 0 3d
insights-influxdb-0 1/1 Running 0 3d
sm-database-nuodb-cluster0-demo-0 1/1 Running 0 10d
sm-database02-nuodb-cluster0-hockeydb01-0 3/3 Running 0 9d
te-database-nuodb-cluster0-demo-68fddff796-5xdxx 1/1 Running 0 10d
te-database02-nuodb-cluster0-hockeydb01-856568f5c7-r7sqh 3/3 Running 0 9d
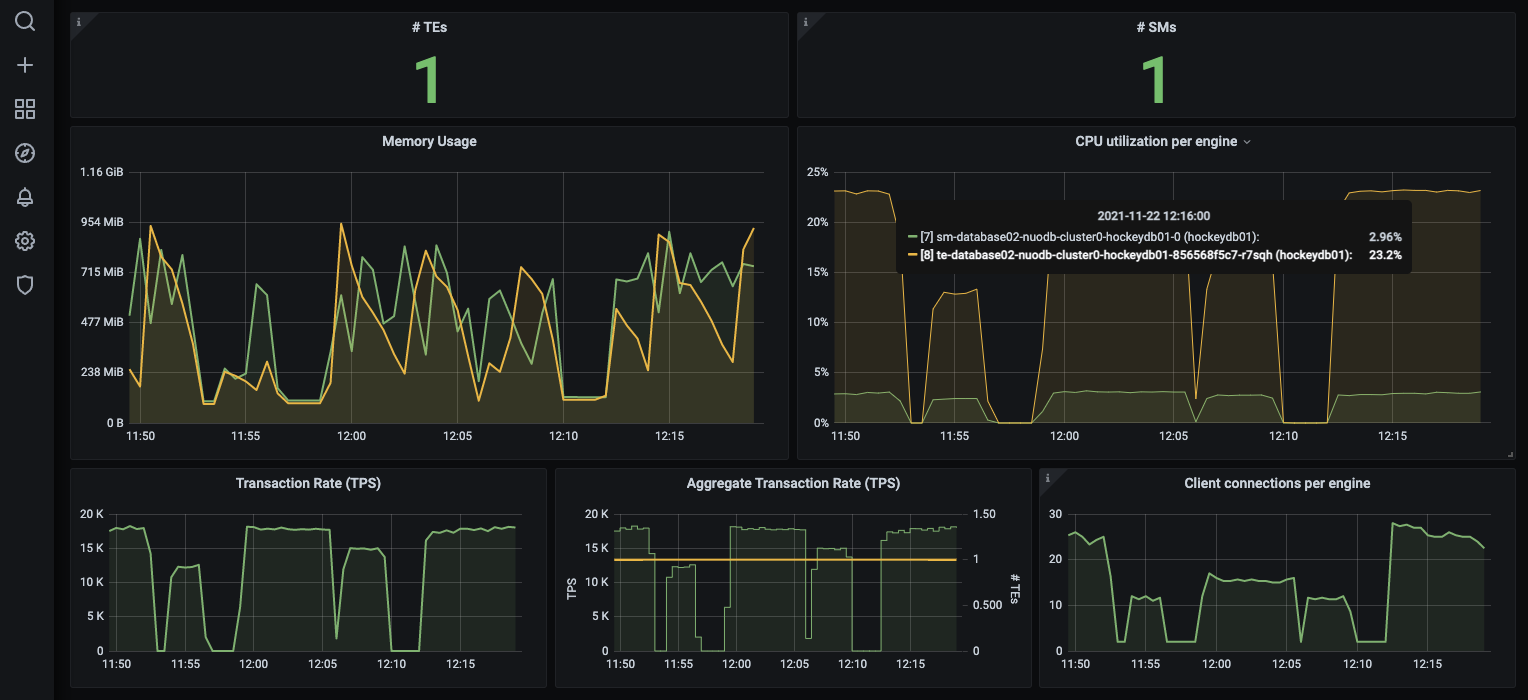
ycsb-load0-dx5sh 1/1 Running 0 10sAfter a few minutes of running the pod we can see the execution load in NuoDB Insights. In the example below , with a single NuoDB TE and single YCSB app running, NuoDB is processing 19K SQL TPS and the TE is running at about 26% CPU.
Next, add another YCSB application (which will double the SQL workload) by running the following command:
$> kubectl -n nuodb apply -f https://raw.githubusercontent.com/colussim/NuoDB/main/Deployer-YSCB/nuodb-ycsb-1.yaml
replicationcontroller/ycsb-load1 createdVerify the pods are running :
$> kubectl get pods -n nuodb -o wide
AME READY STATUS RESTARTS AGE
admin-nuodb-cluster0-0 3/3 Running 0 10d
insights-grafana-57ff765c78-fsc2w 2/2 Running 0 3d
insights-influxdb-0 1/1 Running 0 3d
sm-database-nuodb-cluster0-demo-0 1/1 Running 0 10d
sm-database02-nuodb-cluster0-hockeydb01-0 3/3 Running 0 9d
te-database-nuodb-cluster0-demo-68fddff796-5xdxx 1/1 Running 0 10d
te-database02-nuodb-cluster0-hockeydb01-856568f5c7-r7sqh 3/3 Running 0 9d
ycsb-load0-dx5sh 1/1 Running 0 60s
ycsb-load1-grc65 1/1 Running 0 8sWith NuoDB, you can scale out and scale back your processes with no interruption to the application. To scale the TEs, run the following command:
$> kubectl -n nuodb scale deployment te-database02-nuodb-cluster0-hockeydb01 --replicas=2
deployment.apps/te-database02-nuodb-cluster0-hockeydb01 scaled
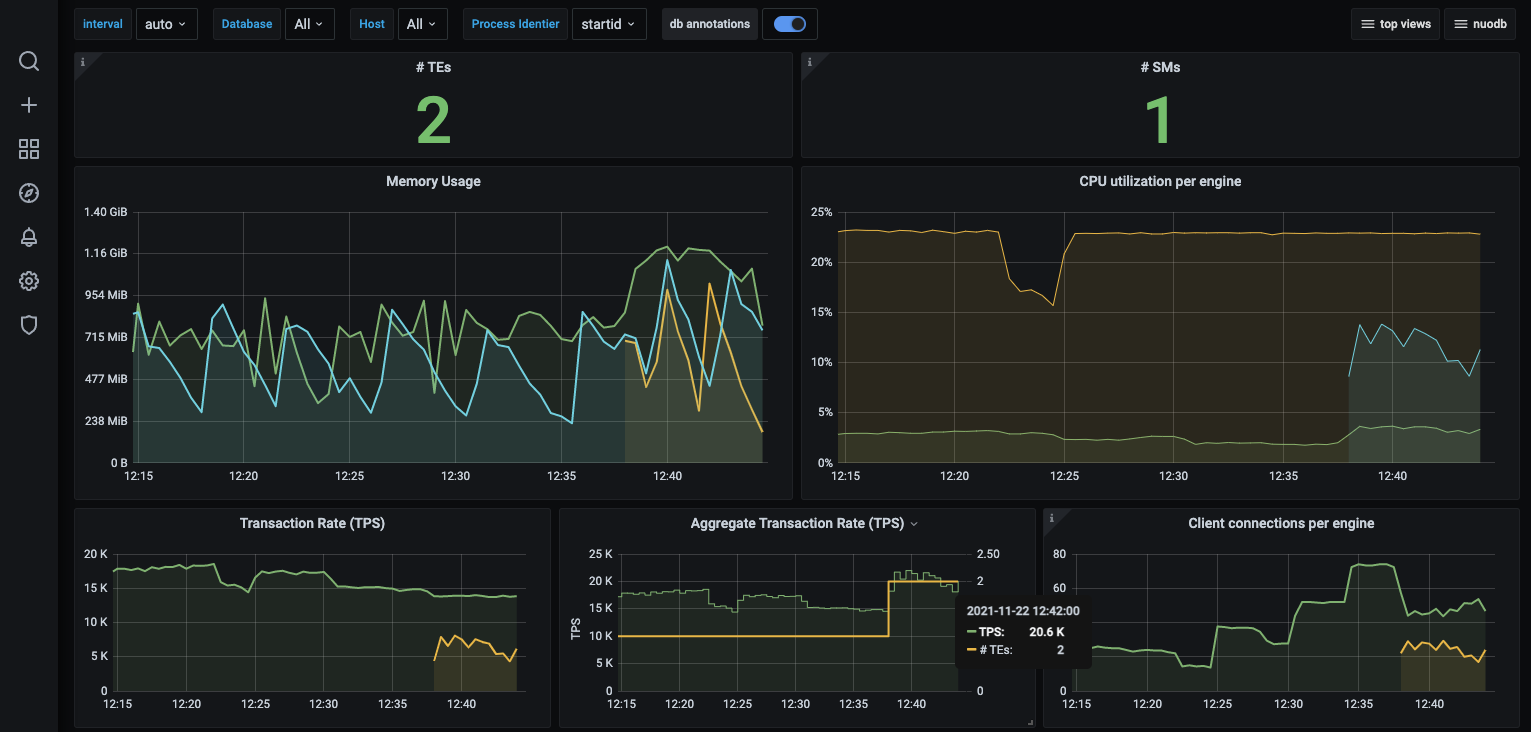
$>The graph below shows us that both TEs are now handling the YCSB SQL workload equally, 20k SQL TPS each.
You can take this benchmark further by running multiple YCSB applications, and scaling up the TE processes. You will notice that the results are stable and NuoDB scales well
Continuous Availability
To demonstrate NuoDB’s resilience to failure and continuous availability, remove a running Transaction Engine (TE) container to simulate a hardware failure or reboot one of the nodes …. You can see that the SQL load will be redistributed to the remaining TE. This type of resilience is also available for administration services and storage managers. To remove a TE engine, just type this command :
$> kubectl -n nuodb scale deployment te-database02-nuodb-cluster0-hockeydb01 --replicas=1
eployment.apps/te-database02-nuodb-cluster0-hockeydb01 scaled
$>In our kubernetes configuration we already have resiliency, as we had already managed the desired number of TEs. So if a process is lost for any reason, the container management system will restart it in just a few seconds. That’s why we set the number of TEs set to 1.If we had killed the pod: te-database-nuodb-cluster0-demo-68fddff796-5xdxx , the orchestration process would have automatically started another TE process.
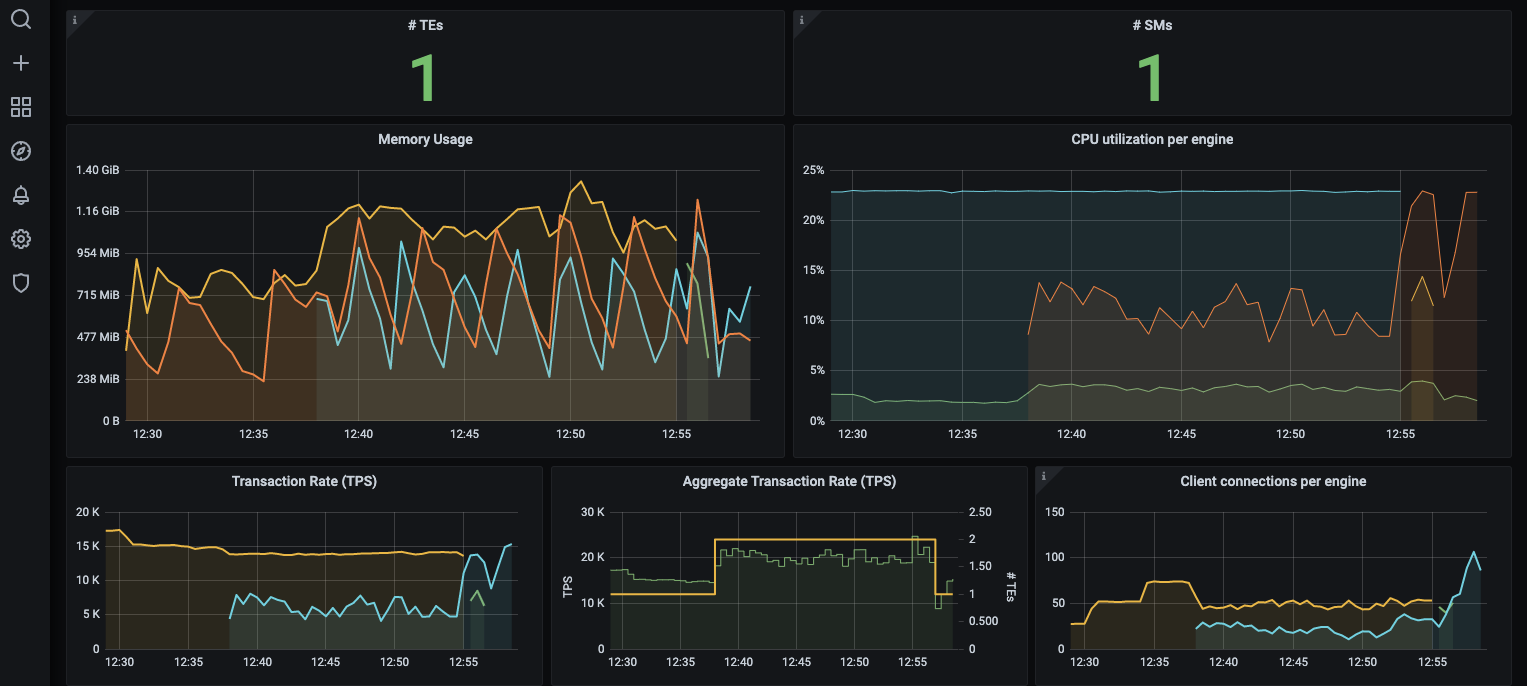
The graph below shows that the number of TEs has decreased to one and the remaining TE is still processing SQL transactions. The aggregate TPS has remained the same and that the application continues to run even though NuoDB has lost one of its TEs.
Conclusion
We saw how the client load is shared when scaling the number of TEs and how the client application was able to recover and continue without data loss when one of the TEs was deliberately shut down. This reactive scalability shows how NuoDB provides continuous availability, even in the event of hardware, network or other failures. When NuoDB is deployed on multiple hosts (one for each engine), application performance can improve dramatically.
However, the community edition has one limitation. If we repeat the last test, but shut down the SM instead, the application will fail because there is no second SM to take over. NuoDB Enterprise Edition removes this restriction by allowing as many TEs and SMs as you want.
Resources :
 YCSB Benchmark Guide
YCSB Benchmark Guide Yahoo! Cloud Serving Benchmark (YCSB)
Yahoo! Cloud Serving Benchmark (YCSB)
 nuodb/ycsb
nuodb/ycsb