Using HELM Chart to Deploying Longhorn to an Amazon Kubernetes Cluster using Terraform
After having been interested in the pure kubernetes storage management part proposed by HPE : HPE Ezmeral Data Fabric (formerly MapR Data Platform) delivered with their large scale containerized application deployment and management tool : HPE Ezmeral Container Platform,as well as has OpenEBS which is a storage solution for Kubernetes , it is a broadly deployed open source storage platform that provides persistent and containerized block storage for DevOps and container environments on Kubernetes. OpenEBS adopts Container Attached Storage (CAS) approach. I wanted to test another Kubernetes storage solution of the same type as OpenEBS.
I looked into Longhorn ! ![]() , it is an open source lightweight, reliable and easy to use distributed block storage system for Kubernetes.
Longhorn is a project initially developed by Rancher and is part of the “Sandbox projects” of the Cloud Native Computing Foundation (CNCF).
, it is an open source lightweight, reliable and easy to use distributed block storage system for Kubernetes.
Longhorn is a project initially developed by Rancher and is part of the “Sandbox projects” of the Cloud Native Computing Foundation (CNCF).
Features
Highly available persistent storage for Kubernetes
In the past, ITOps and DevOps have found it hard to add replicated storage to Kubernetes clusters. As a result many non-cloud-hosted Kubernetes clusters don’t support persistent storage. External storage arrays are non-portable and can be extremely expensive.
Longhorn delivers simplified, easy to deploy and upgrade, 100% open source, cloud-native persistent block storage without the cost overhead of open core or proprietary alternatives.
Easy incremental snapshots and backups
Longhorn’s built-in incremental snapshot and backup features keep the volume data safe in or out of the Kubernetes cluster.
Scheduled backups of persistent storage volumes in Kubernetes clusters is simplified with Longhorn’s intuitive, free management UI.
Cross-cluster disaster recovery
External replication solutions will recover from a disk failure by re-replicating the entire data store. This can take days, during which time the cluster performs poorly and has a higher risk of failure.
Using Longhorn, you can control the granularity to the maximum, easily create a disaster recovery volume in another Kubernetes cluster and fail over to it in the event of an emergency.
If your main cluster fails, you can bring up the app in the DR cluster quickly with a defined RPO and RTO.

For more details on the architecture of Longhorn see the following link:

In this post you will see :
- How to Provisioning EBS volume with Terraform
- How to deploy Longhorn with Terraform
- Connect to the Longhorn dashboard
- Creating a Storage Class
- Provisioning a Persistent Volume Claim
- Deploying a MySQL instance on an Longhorn storage
- Restore Database
Prerequisites
Before you get started, you’ll need to have these things:
- Terraform > 0.13.x
- kubectl installed on the compute that hosts terraform
- An AWS account with the IAM permissions
- AWS CLI : the AWS CLI Documentation
- AWS key-pair Create a key pair using Amazon EC2
- Kubernetes cluster running
- HELM > 3.0.x
- MySQL client
In a production configuration it is recommended to have 3 workers nodes in its kubernetes cluster. In the test configuration we have only 2 workers nodes, I took the configuration deployed in this post: Deploy a Kubernetes cluster using Ansible in AWS
Initial setup
- Clone the repository and install the dependencies:
$ git clone https://github.com/colussim/terraform-longhorn-k8s-aws.git
$ cd terraform-longhorn-k8s-aws
terraform-longhorn-k8s-aws $> - We will have to access the Kubernetes cluster api from our terraform workstation with the public IP address of our master node :
Connect to your master node and run the following commands: (we will add the public ip address of our master node) –apiserver-cert-extra-sans=ip_private_worker01, ip_private_worker02, ip_public_master01
%> sudo kubeadm init phase certs all --apiserver-advertise-address=0.0.0.0 --apiserver-cert-extra-sans=x.x.x.x, x.x.x.x, x.x.x.x
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Using existing ca certificate authority
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [ip-10-1-0-99 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.1.0.99 54.210.93.212]
[certs] Using existing apiserver-kubelet-client certificate and key on disk
[certs] Using existing front-proxy-ca certificate authority
[certs] Using existing front-proxy-client certificate and key on disk
[certs] Using existing etcd/ca certificate authority
[certs] Using existing etcd/server certificate and key on disk
[certs] Using existing etcd/peer certificate and key on disk
[certs] Using existing etcd/healthcheck-client certificate and key on disk
[certs] Using existing apiserver-etcd-client certificate and key on disk
[certs] Using the existing "sa" key
%> sudo systemctl restart kubelet
%>-
Get your kubernetes cluster configuration access file /etc/kubernetes1.22/admin.conf and copy it to the local directory: ~/terraform-longhorn-k8s-aws/kubeconfig/config
-
Test api acces with kubectl command from our terraform workstation. You should get a similar result :
$ export KUBECONFIG=~/terraform-longhorn-k8s-aws/kubeconfig/config
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-1-0-235 Ready worker 4d15h v1.22.1
ip-10-1-0-99 Ready control-plane,master 4d15h v1.22.1
ip-10-1-1-59 Ready worker 4d15h v1.22.1-
Copy your ssh key to access your cluster nodes into the ssh-keys directory (~/terraform-longhorn-k8s-aws/ssh-keys)
-
Install the dependencies:
$ cd terraform-longhorn-k8s-aws/addstorage
terraform-longhorn-k8s-aws/addstorage $> terraform init
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Installing hashicorp/aws v3.59.0...
- Installed hashicorp/aws v3.59.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.We are going to add two volumes of type EBS (Elastic Block Store) of 20 Gb to each of our Worker instances . And we will deploy our Longhorn afterwards which will use these volumes.
Provisioning EBS volume and attaching it to a Terraform EC2 worker instance.
Elastic Block Store are disk volumes which can be attached to EC2 instances. EBS volumes exist independently, meaning their lifecycle is not dependent on the EC2 instance they are attached to.
Step 1 : get id for each worker instance : run this scripts (or get id in AWS Console) :
terraform-longhorn-k8s-aws/addstorage $> ./Getinstance_workers_id.sh
Modify the variables.tf file :
Replace the default value of the variable worker_instance_id with :
default = ["i-0717cb91ccc3ebfd3", "i-0489a59e7ae953478"]
terraform-longhorn-k8s-aws/addstorage $>Modify the file variables.tf in the directory : addstorage You should modify the worker_instance_id entry with the id values of your instances and the worker_zone entry with your working zone.
variable "volume_count" {
default = 2
description = "Number of disk by instance"
}
variable "volume_size" {
default = "20"
description = "Size for volume default : 20 GB"
}
variable "device_names" {
type = list
default = ["/dev/sdf", "/dev/sdg", "/dev/sdg", "/dev/sdf"]
description = "device name"
}
variable "worker_instance_id" {
type = list
default = ["i-02008589e537d1c55", "i-0735750894d041771"]
description = "Instance id for worker node"
}
variable "worker_instance_count" {
default = 2
description = "Number worker Instance"
}
variable "worker_zone" {
default = "us-east-1a"
}Usage
Create EBS volume and attaching it to worker instance
terraform-longhorn-k8s-aws/addstorage $> terraform applyTear down the whole Terraform plan with :
terraform-longhorn-k8s-aws/addstorage $> terraform destroy -forceIn a few seconds your volumes are created
aws_ebs_volume.ebs_volume[0]: Creating...
aws_ebs_volume.ebs_volume[2]: Creating...
aws_ebs_volume.ebs_volume[1]: Creating...
aws_ebs_volume.ebs_volume[3]: Creating...
aws_ebs_volume.ebs_volume[3]: Still creating... [10s elapsed]
aws_ebs_volume.ebs_volume[2]: Still creating... [10s elapsed]
aws_ebs_volume.ebs_volume[1]: Still creating... [10s elapsed]
aws_ebs_volume.ebs_volume[0]: Still creating... [10s elapsed]
aws_ebs_volume.ebs_volume[1]: Creation complete after 12s [id=vol-0956daff34eaa5e17]
aws_ebs_volume.ebs_volume[3]: Creation complete after 12s [id=vol-0e0c96da65c6c82e9]
aws_ebs_volume.ebs_volume[2]: Creation complete after 12s [id=vol-032dd6b849c65f953]
aws_ebs_volume.ebs_volume[0]: Creation complete after 12s [id=vol-0e225c68920f745f1]
aws_volume_attachment.volume_attachement[0]: Creating...
aws_volume_attachment.volume_attachement[1]: Creating...
aws_volume_attachment.volume_attachement[2]: Creating...
aws_volume_attachment.volume_attachement[3]: Creating...
aws_volume_attachment.volume_attachement[2]: Still creating... [10s elapsed]
aws_volume_attachment.volume_attachement[3]: Still creating... [10s elapsed]
aws_volume_attachment.volume_attachement[0]: Still creating... [10s elapsed]
aws_volume_attachment.volume_attachement[1]: Still creating... [10s elapsed]
aws_volume_attachment.volume_attachement[2]: Still creating... [20s elapsed]
aws_volume_attachment.volume_attachement[1]: Still creating... [20s elapsed]
aws_volume_attachment.volume_attachement[0]: Still creating... [20s elapsed]
aws_volume_attachment.volume_attachement[3]: Still creating... [20s elapsed]
aws_volume_attachment.volume_attachement[2]: Creation complete after 23s [id=vai-3835379982]
aws_volume_attachment.volume_attachement[1]: Creation complete after 23s [id=vai-1141740102]
aws_volume_attachment.volume_attachement[0]: Creation complete after 23s [id=vai-2298066267]
aws_volume_attachment.volume_attachement[3]: Creation complete after 23s [id=vai-2426290266]
Apply complete! Resources: 8 added, 0 changed, 0 destroyed.Use the lsblk (on each worker nodes) to view any volumes that were mapped at launch but not formatted and mounted.
terraform-longhorn-k8s-aws $> ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -i ssh-keys/admin.pem ec2-user@x.x.x.x lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 10G 0 disk
├─nvme0n1p1 259:1 0 300M 0 part /boot
└─nvme0n1p2 259:2 0 9.7G 0 part /
nvme1n1 259:3 0 20G 0 disk
nvme2n1 259:4 0 20G 0 disk
$we have our two 20 Gb disks (nvme1n1 nvme2n1) attached to our instance.
We will create a 20GB partition on each disk and on each worker node. Run these two commands on each worker node :
$ sudo echo 'type=83' | sudo sfdisk /dev/nvme1n1
Checking that no-one is using this disk right now ... OK
Disk /dev/nvme1n1: 20 GiB, 21474836480 bytes, 41943040 sectors
Disk model: Amazon Elastic Block Store
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xf5aaf733.
/dev/nvme1n1p1: Created a new partition 1 of type 'Linux' and of size 20 GiB.
/dev/nvme1n1p2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xf5aaf733
Device Boot Start End Sectors Size Id Type
/dev/nvme1n1p1 2048 41943039 41940992 20G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
$
$
$sudo echo 'type=83' | sudo sfdisk /dev/nvme2n1
Checking that no-one is using this disk right now ... OK
Disk /dev/nvme2n1: 20 GiB, 21474836480 bytes, 41943040 sectors
Disk model: Amazon Elastic Block Store
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0x0414b651.
/dev/nvme2n1p1: Created a new partition 1 of type 'Linux' and of size 20 GiB.
/dev/nvme2n1p2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0x0414b651
Device Boot Start End Sectors Size Id Type
/dev/nvme2n1p1 2048 41943039 41940992 20G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Let’s check that our two partitions are created on each worker node: We should have both partitions : nvme1n1p1 and nvme2n1p1
terraform-longhorn-k8s-aws $> ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -i ssh-keys/admin.pem ec2-user@x.x.x.x lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 10G 0 disk
├─nvme0n1p1 259:1 0 300M 0 part /boot
└─nvme0n1p2 259:2 0 9.7G 0 part /
nvme1n1 259:3 0 20G 0 disk
└─nvme1n1p1 259:5 0 20G 0 part
nvme2n1 259:4 0 20G 0 disk
└─nvme2n1p1 259:6 0 20G 0 part
$Since Longhorn doesn’t currently support sharding between the different disks. It is recommended to use LVM to aggregate all the disks for Longhorn into a single partition, so it can be easily extended in the future.
We will create a Group Volume vgdata with both disks and a logical volume lvdata01 striped on both disks, and this on each node. The logical volume will be mounted on the Longhorn default directory: /var/lib/longhorn. It will be formatted in ext4
We execute these operations on each worker node.
$ sudo pvcreate -f /dev/nvme1n1p1
$ sudo pvcreate -f /dev/nvme2n1p1
$ sudo vgcreate vgdata /dev/nvme1n1p1 /dev/nvme2n1p1
$ sudo lvcreate -L 30G -i 2 -I 64 /dev/vgdata -n lvdata01
$ mkdir -p /var/lib/longhorn
$
$ mkfs.ext4 -O ^64bit,^metadata_csum /dev/vgdata/lvdata01
$ mount -t ext4 /dev/vgdata/lvdata01 /var/lib/longhorn
$so the users need to make sure the alternative path are correctly mounted when the node reboots, e.g. by adding it to fstab. Custom mkfs.ext4 parameters Allows setting additional filesystem creation parameters for ext4. For older host kernels it might be necessary to disable the optional ext4 metadata_csum feature by specifying -O ^64bit,^metadata_csum
Now let’s install our distributed storage Longhorn.
Deploy Longhorn:
First set setup Terraform configuration :
Edit the maint.tf file in directory longhorn et change a path of your kubernetes cluster configuration access file (~/terraform-longhorn-k8s-aws/kubeconfig) and config_context value (the information is in your access file : ~/terraform-longhorn-k8s-aws/kubeconfig/config)
terraform-longhorn-k8s-aws $> cd longhorn
terraform-longhorn-k8s-aws/longhorn $> terraform apply
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/kubernetes versions matching ">= 2.0.0"...
- Finding latest version of hashicorp/helm...
- Installing hashicorp/kubernetes v2.5.0...
- Installed hashicorp/kubernetes v2.5.0 (signed by HashiCorp)
- Installing hashicorp/helm v2.3.0...
- Installed hashicorp/helm v2.3.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
terraform-longhorn-k8s-aws/longhorn $>If you use the terraform apply command without parameters the default values will be those defined in the variables.tf file.
This will do the following :
- create a namespace
- create a deployment object for Longhorn
terraform-longhorn-k8s-aws/longhorn $> terraform apply
kubernetes_namespace.Longhorn-namespace: Creating...
kubernetes_namespace.Longhorn-namespace: Creation complete after 0s [id=longhorn-system]
helm_release.longhorn: Creating...
helm_release.longhorn: Still creating... [10s elapsed]
helm_release.longhorn: Still creating... [20s elapsed]
helm_release.longhorn: Still creating... [30s elapsed]
helm_release.longhorn: Still creating... [40s elapsed]
helm_release.longhorn: Creation complete after 42s [id=longhorn]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
terraform-longhorn-k8s-aws/longhorn $>Tear down the whole Terraform plan with :
terraform-longhorn-k8s-aws/longhorn $> terraform destroy -forceResources can be destroyed using the terraform destroy command, which is similar to terraform apply but it behaves as if all of the resources have been removed from the configuration.
Verifying installation
Verify pods:
Wait for some time to see all the pods in the running state in the longhorn-system namespace
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-75588bff58-8d7fl 1/1 Running 0 59s
csi-attacher-75588bff58-mcqzt 1/1 Running 0 59s
csi-attacher-75588bff58-vvhdx 1/1 Running 0 59s
csi-provisioner-6968cf94f9-bzgtt 1/1 Running 0 58s
csi-provisioner-6968cf94f9-rx9x7 1/1 Running 0 58s
csi-provisioner-6968cf94f9-wss2f 1/1 Running 0 58s
csi-resizer-5c88bfd4cf-gh65x 1/1 Running 0 58s
csi-resizer-5c88bfd4cf-gwtj2 1/1 Running 0 58s
csi-resizer-5c88bfd4cf-xfz6w 1/1 Running 0 58s
csi-snapshotter-69f8bc8dcf-mm6lx 1/1 Running 0 58s
csi-snapshotter-69f8bc8dcf-nq9bb 1/1 Running 0 58s
csi-snapshotter-69f8bc8dcf-r5r6j 1/1 Running 0 58s
engine-image-ei-0f7c4304-crqvm 1/1 Running 0 65s
engine-image-ei-0f7c4304-smd7w 1/1 Running 0 65s
instance-manager-e-bec52686 1/1 Running 0 63s
instance-manager-e-dabb6cab 1/1 Running 0 66s
instance-manager-r-d0a1f4bd 1/1 Running 0 65s
instance-manager-r-ff22faa1 1/1 Running 0 62s
longhorn-csi-plugin-vt6c8 2/2 Running 0 58s
longhorn-csi-plugin-zpjxf 2/2 Running 0 58s
longhorn-driver-deployer-7c8f55ddfd-2c678 1/1 Running 0 81s
longhorn-manager-2gcpm 1/1 Running 0 82s
longhorn-manager-mjhcj 1/1 Running 1 (67s ago) 82s
longhorn-ui-7545689d69-b4n6p 1/1 Running 0 81s
$A default storage class is created: :
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 3h45mConnect to dashbord
To access the dashboard, you need to find the IP of the cluster on which the longhorn-frontend service binds :
$ kubectl -n longhorn-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
csi-attacher ClusterIP 10.103.33.214 <none> 12345/TCP 4h15m
csi-provisioner ClusterIP 10.104.153.127 <none> 12345/TCP 4h15m
csi-resizer ClusterIP 10.110.80.2 <none> 12345/TCP 4h15m
csi-snapshotter ClusterIP 10.103.99.175 <none> 12345/TCP 4h15m
longhorn-backend ClusterIP 10.106.219.184 <none> 9500/TCP 4h15m
longhorn-frontend ClusterIP 10.110.79.248 <none> 80/TCP 4h15m
$In our case the ip address is 10.110.79.248. We are going to connect with ssh on our master and do a port forwarding from port 80 to port 8888 for example (take an available port on your workstation).
Open a SSH tunnel:
$ ssh -L 8888:10.110.79.248:80 -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -i ssh-keys/id_rsa_aws ec2-user@ip_external_master_nodeNow you can access the dashboard on your computer at http://localhost:8888.

Deploying a Mysql instance
We start by creating our storage class : longhorn-demo
- Create a storage class
From our workstation (or if you are connected to the master note run the command: kubectl apply -f https://raw.githubusercontent.com/colussim/terraform-longhorn-k8s-aws/main/longhorn/k8s/storageclass.yaml) run the following commands:
terraform-longhorn-k8s-aws/longhorn $> cd k8s
terraform-longhorn-k8s-aws/longhorn/k8s $> kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/longhorn-demo created
terraform-longhorn-k8s-aws/longhorn/k8s $>- Check that the storage class is created
terraform-longhorn-k8s-aws/longhorn/k8s $> kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 4h57m
longhorn-demo driver.longhorn.io Delete Immediate true 56s
terraform-longhorn-k8s-aws/longhorn/k8s $>- Create a MySQL Server instance:
We will now deploy our MySQL instance via terraform.
The deployment variables are initialized in the file variables.tf.
Run the following commands:
terraform-longhorn-k8s-aws/longhorn/k8s $> cd ../../mysql
terraform-longhorn-k8s-aws/mysql $> terraform init
terraform-longhorn-k8s-aws/mysql $> terraform apply
ubernetes_secret.sqlsecret: Creating...
kubernetes_namespace.mysql-namespace: Creating...
kubernetes_service.mysql-deployment-student1: Creating...
kubernetes_persistent_volume_claim.mysql-pvc-student1: Creating...
kubernetes_deployment.mysql-deployment-student1: Creating...
kubernetes_namespace.mysql-namespace: Creation complete after 0s [id=student1]
kubernetes_secret.sqlsecret: Creation complete after 0s [id=student1/sqlsecret]
kubernetes_service.mysql-deployment-student1: Creation complete after 0s [id=student1/mysql-deployment-student1-service]
kubernetes_persistent_volume_claim.mysql-pvc-student1: Creation complete after 4s [id=student1/pvc-mysql-data01]
kubernetes_deployment.mysql-deployment-student1: Still creating... [10s elapsed]
kubernetes_deployment.mysql-deployment-student1: Still creating... [20s elapsed]
kubernetes_deployment.mysql-deployment-student1: Creation complete after 27s [id=student1/mysql-deployment-student1]
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
terraform-longhorn-k8s-aws/mysql $>If you use the terraform apply command without parameters the default values will be those defined in the variables.tf file.
This will do the following :
- create a namespace
- create of the secret object for the password sa for the MS SQL Server instance
- the password is base64 encoded, in this example the password is : Bench123
- create a PVC : Persistant Volume Claim
- create a deployment object for MySQL Server : create a MySQL Server instance
- create a service object for MySQL Server instance:
Tear down the whole Terraform plan with :
terraform-longhorn-k8s-aws/mysql $> terraform destroy -forceResources can be destroyed using the terraform destroy command, which is similar to terraform apply but it behaves as if all of the resources have been removed from the configuration.
You can also see the PVC created in the UI of Longhorn (or with command kubectl get pvc -n student1) :

Remote control
Check if your MySQL instance works:
erraform-longhorn-k8s-aws/mysql $> kubectl get pods -n student1
NAME READY STATUS RESTARTS AGE
mysql-deployment-student1-6bf9d4c965-tngnl 1/1 Running 0 5m
terraform-longhorn-k8s-aws/mysql $>To access the MySQL Server Instance :
terraform-longhorn-k8s-aws/mysql $> MYSQLPOD=`kubectl -n student1 get pods -l app=mysql | grep Running | grep 1/1 | awk '{print $1}'`
terraform-longhorn-k8s-aws/mysql $> kubectl -n student1 exec -it $MYSQLPOD -- mysql -u root -pBench123 -e 'select @@version'
+-----------+
| @@version |
+-----------+
| 8.0.25 |
+-----------+
terraform-longhorn-k8s-aws/mysql $>Now that we are inside the shell, we can populate create a sample database and table.
Step1 : get a sample database
terraform-longhorn-k8s-aws/mysql $> wget http://techlabnews.com/dbtest/test_db-master.zip
terraform-longhorn-k8s-aws/mysql $> unzip test_db-master.zip
terraform-longhorn-k8s-aws/mysql $>Step2 : copy The Employees database files in POD :
terraform-longhorn-k8s-aws/mysql $> kubectl -n student1 cp test_db-master student1/$MYSQLPOD:/home
$Verified that the files are copied correctly :
terraform-longhorn-k8s-aws/mysql $> kubectl -n student1 exec -it $MYSQLPOD -- ls /home/test_db-master
Changelog load_dept_emp.dump objects.sql
README.md load_dept_manager.dump sakila
employees.sql load_employees.dump show_elapsed.sql
employees_partitioned.sql load_salaries1.dump sql_test.sh
employees_partitioned_5.1.sql load_salaries2.dump test_employees_md5.sql
images load_salaries3.dump test_employees_sha.sql
load_departments.dump load_titles.dump test_versions.sh
terraform-longhorn-k8s-aws/mysql $>Step3 : run the SQL scripts for creating the employee data base and loading the data
terraform-longhorn-k8s-aws/mysql $> cd test_db-master
terraform-longhorn-k8s-aws/mysql $> kubectl -n student1 exec -it $MYSQLPOD -- mysql -u root -pBench123 < employees.sql
INFO
CREATING DATABASE STRUCTURE
INFO
storage engine: InnoDB
INFO
LOADING departments
INFO
LOADING employees
INFO
LOADING dept_emp
INFO
LOADING dept_manager
INFO
LOADING titles
INFO
LOADING salaries
data_load_time_diff
00:00:52
terraform-longhorn-k8s-aws/mysql $>Let’s run a few queries on the table.
terraform-longhorn-k8s-aws/mysql $> kubectl -n student1 exec -it $MYSQLPOD -- mysql -u root -pBench123 employees -e "select count(*) from employees"
+----------+
| count(*) |
+----------+
| 300024 |
+----------+
terraform-longhorn-k8s-aws/mysql $>We have configured the MySQL service in NodePort (we could also have configured it as a LoadBalancer and created an AWS Load Balancer Controller ). For that you will have to modify the file mysqlpod.tf in the section resource “kubernetes_service” “mysql-deployment-student1” replace type=NodePort by type=LoadBalancer
You need to installed an AWS Load Balancer Controller and assigned the MySQL service you can connect to your instance directly using the external IP address.
More information on this link for the installation of a AWS Load Balancer Controller.
In our case we’ll get the port where the service is bound and connect with one of the external ip addresses of one of the cluster nodes and the port.
Get the external port :
terraform-longhorn-k8s-aws/mysql $> kubectl get svc -n student1
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql-deployment-student1-service NodePort 10.101.159.157 <none> 3306:31644/TCP 169m
terraform-longhorn-k8s-aws/mysql $>The external port is : 31644
You can access the MySQL Server instance with your favorite tool like MySQLWorkbench :
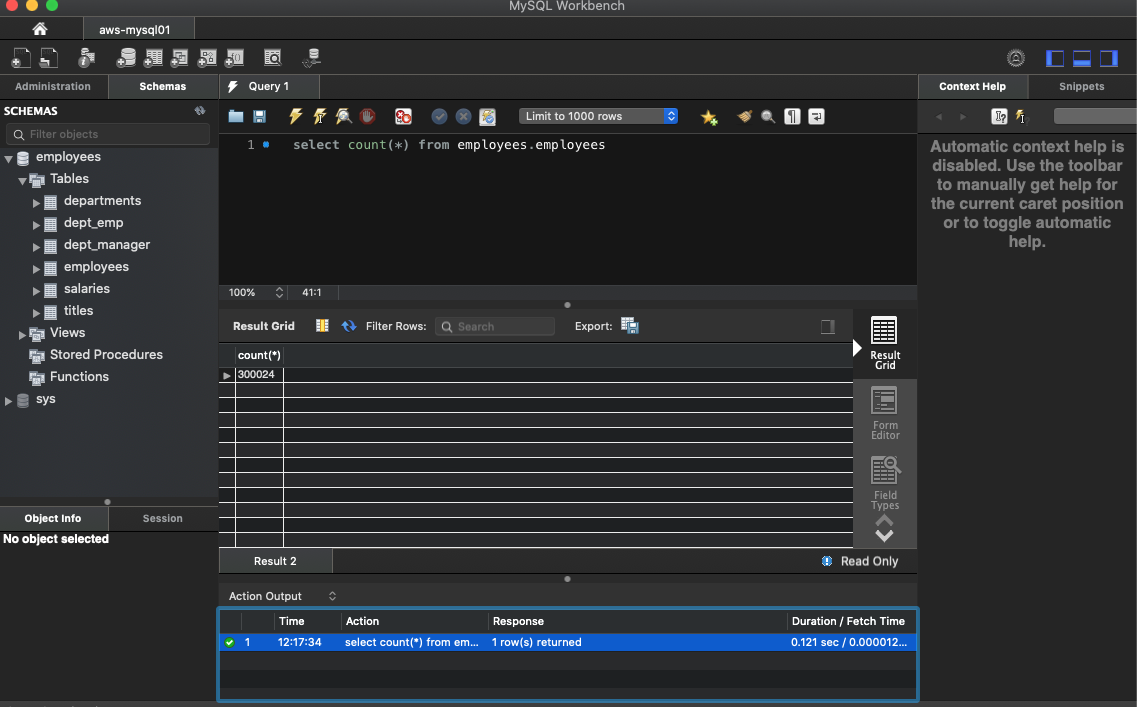
Next Step
Using Volume Snapshot and Clone in Longhorn
Conclusion
Longhorn implements a very complete storage solution for Kubernetes: we have high availability, observability, and integrated backup solutions. Longhorn is quite simple to set up. Most of its use is done through standard Kubernetes mechanisms, which is nice: these are mainly the PersistentVolume, PersistentVolumeClaim, and VolumeSnapshot objects.
All the ingredients are there to deploy this solution in production, but it is just not quite there yet compared to OpenEBS, Mapr and other competitors. I like Longhorn a lot but let’s wait to see its evolution and its new features.
 Longhorn Charts
Longhorn Charts