Following different implementation of kubernetes cluster, I asked myself the question : is that the Persistent Memory Intel Optane would allow optimization of etcd and have a performance gain on Kubernetes clusters ?
It is known that the performance of etcd is strongly dependent on the performance of your storage.Given this, this question is worth asking and saying: If fast storage is needed for etcd to perform well, will even faster storage improve etcd’s performance or will it allow etcd to scale to higher loads ?

 What is etcd ?
What is etcd ?
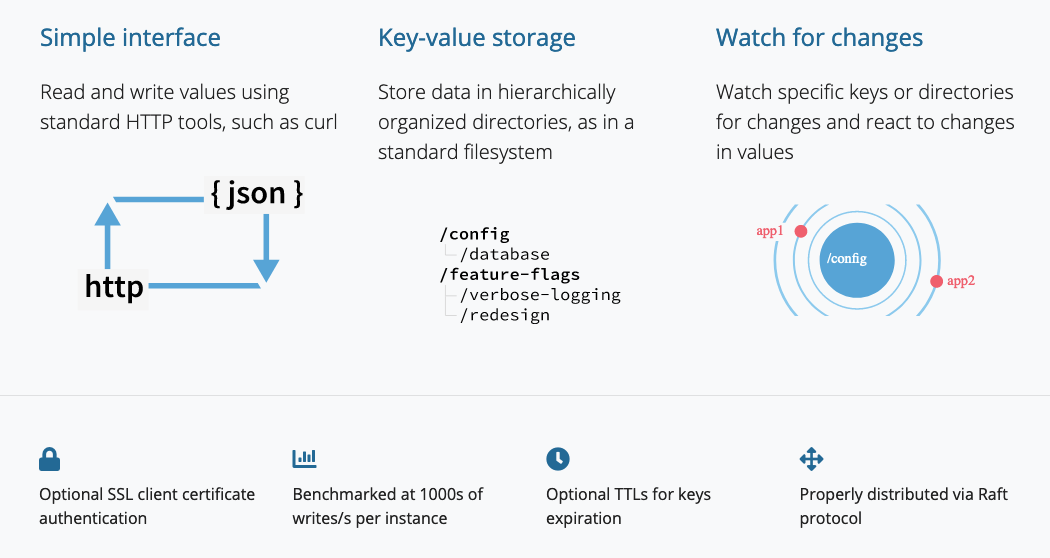
We know that Kubernetes is distributed, it runs on several machines at the same time. So, it needs a distributed database. One that runs on several machines at the same time. One that makes it easy to store data across a cluster and watch for changes to that data.Kubernetes uses etcd as its database.
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines.
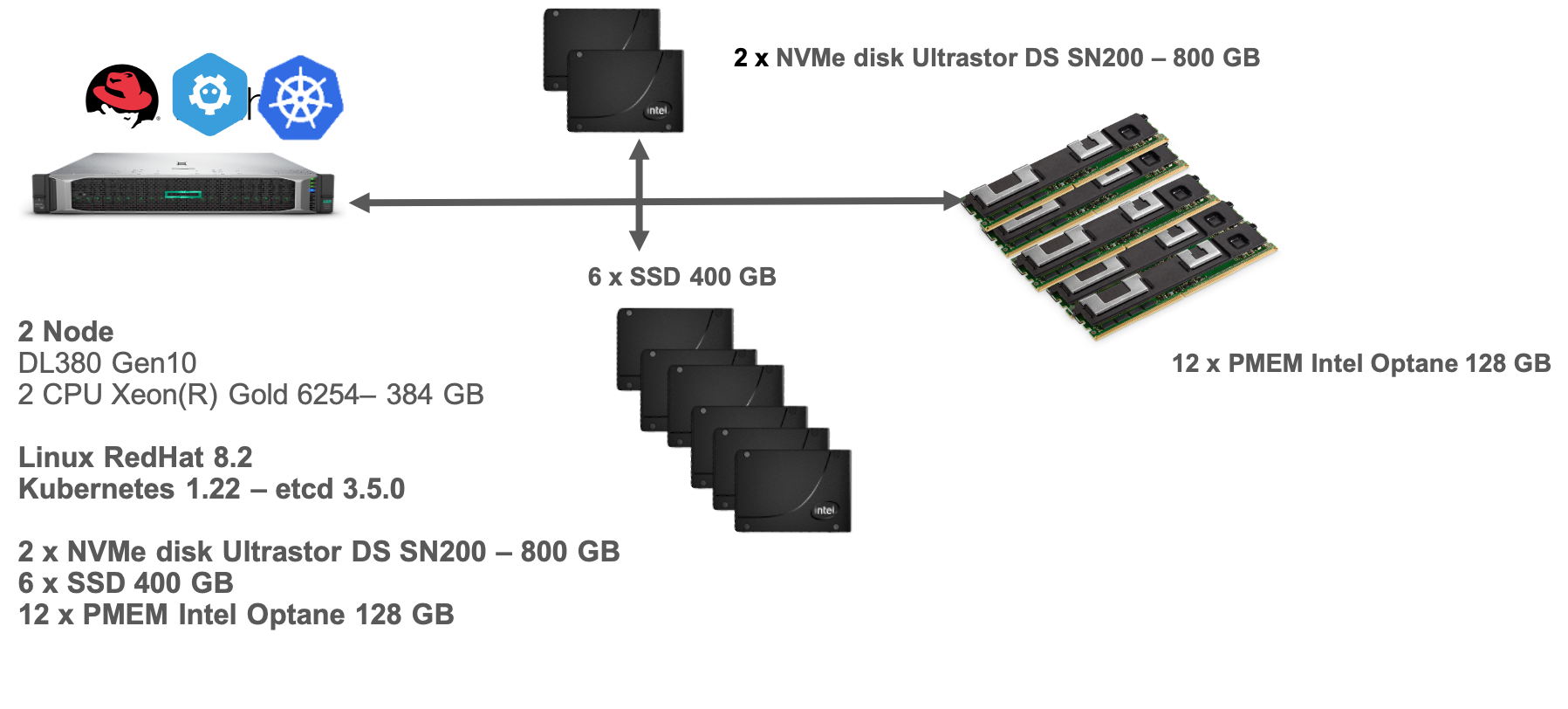
 Infrastructure description
Infrastructure description
The infrastructure of the platform is composed of:
- 1 Master node
- 1 Worker nodes
- Kubernetes 1.25.5 with etcd 3.5.3
- RedHat Enterprise server 8.2
- etcd Benchmark tool
each node included:
- 2 CPU Xeon(R) Gold 6254 – 384 GB
- 12 x PMEM Intel Optane 128 GB distributed evenly among the 12 memory channels
- 6 x SSD 400 GB
- 2 x NVMe disk Ultrastor DS SN200 – 800 GB
I configured the system for App Direct mode and mounted a folder in the pmem0.The pmem0 device is accessible to cores on both sockets but is directly attached to only one of the sockets. I had to test to make sure we were running the etcd server on the socket with the lowest latency and highest bandwidth to the pmem0 device. I recognize that this configuration represents a lot more resources (memory and cores) than what is usually dedicated to an etcd cluster node, but it was the only configuration I had available… Using our this infrastructure and limiting the etcd server to 18 cores, we ran a test scaling the number of clients from 100 to 50 000. We also placed the backing store in different locations, either in the pmem0 directory mounted as above, in an Optane NVMe drive, or on a traditional flash-based SSD. We also used two values for the number of connections per client 50.
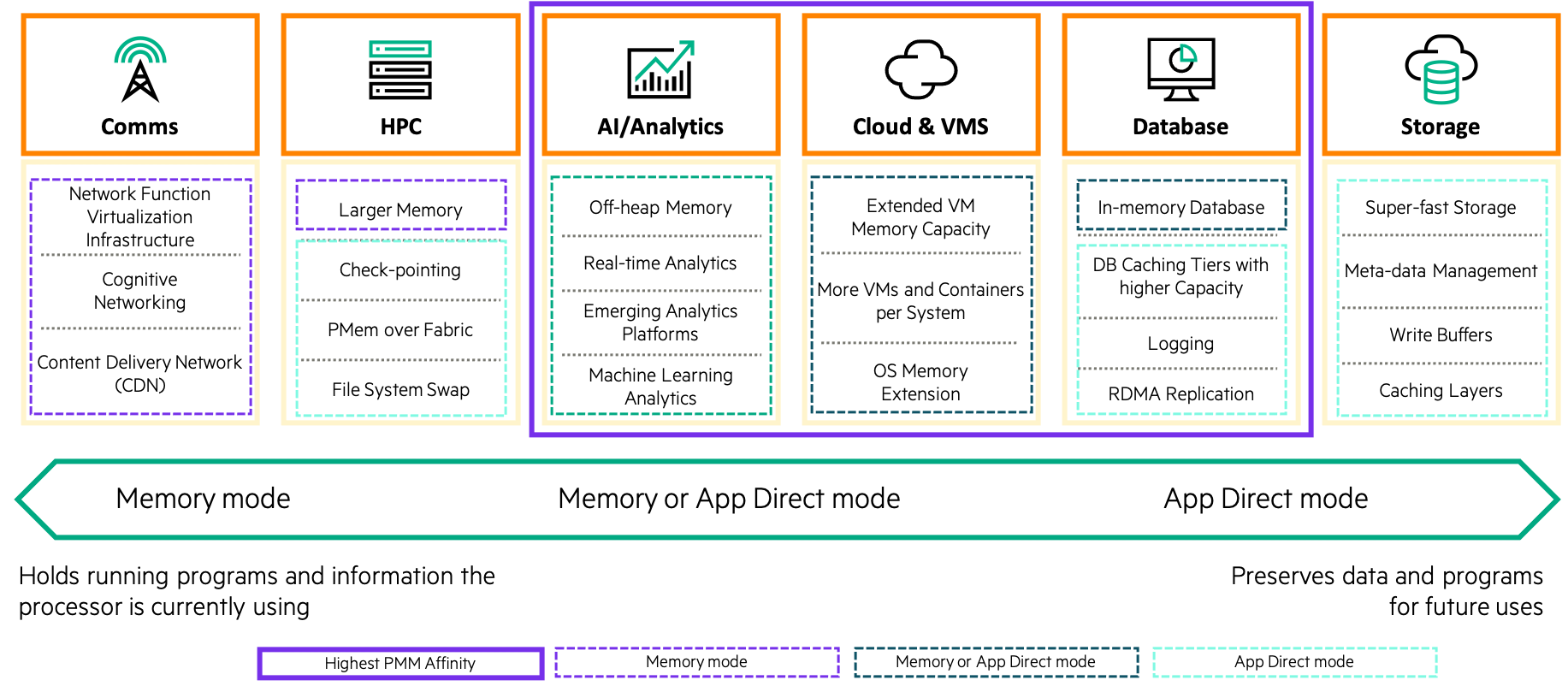
PMEM Operational modes :

Workloads and applicable modes :
For the telemetry part, I used the Prometheus environment and HPE GlancePlus tool for Linux (a bit old but works very well…).
Tests
For the tests I was interested in :
- AVG Request Latency / Number of clients
- CPU Utilization / Number of clients
- Disk IO / Number of clients
- FSYNC AVG/ Number of clients
 AVG Request Latency / Number of clients
AVG Request Latency / Number of clients

The results shown above demonstrate that etcd is not easily able to take advantage of the bandwidth and latency improvements available from PMEM.
It is likely that other bottlenecks exist that prevent taking advantage of PMEM technology.
I looked at the resource usage as the client load increases.
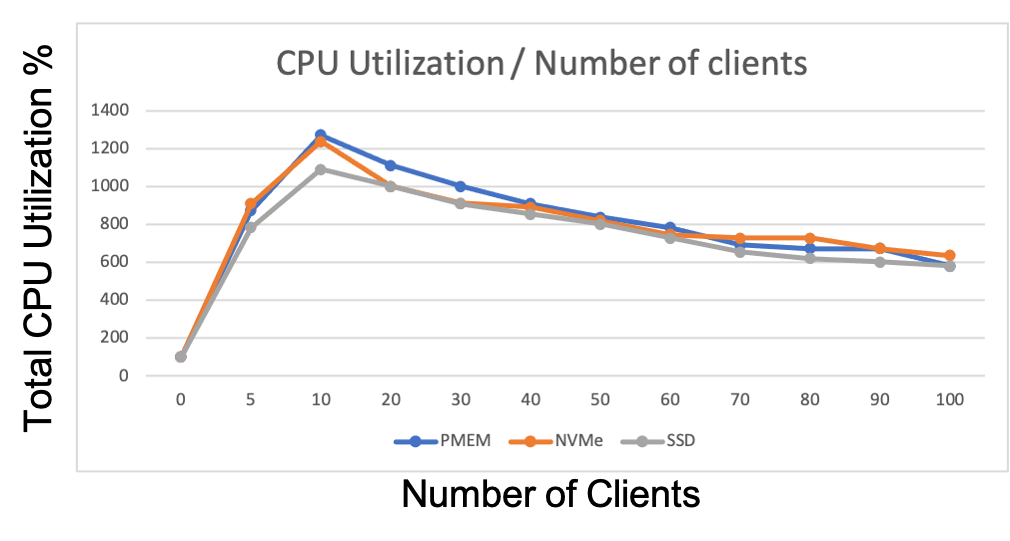
CPU Utilization / Number of clients
The graph below shows how the CPU usage of the etcd server changes as the load increases.
The graph shows that the CPU utilization was always below 1400%, which shows that more than 18 CORES would not bring more performance, we also notice that the CPU load decreases as the load increases. This indicates that the bottleneck is not the CPU.
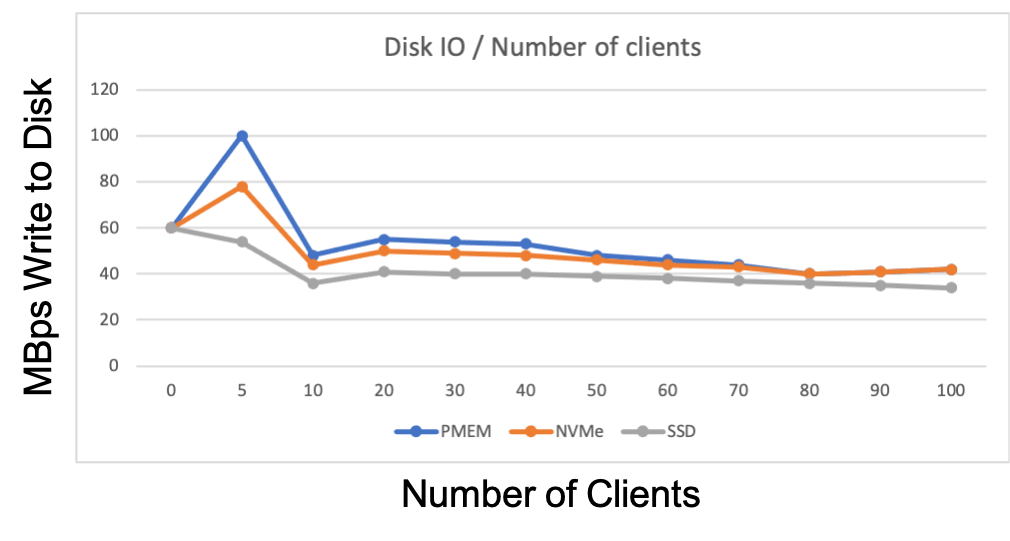
Disk IO / Number of clients
After the CPU load I looked at the disk I/O but nothing abnormal :
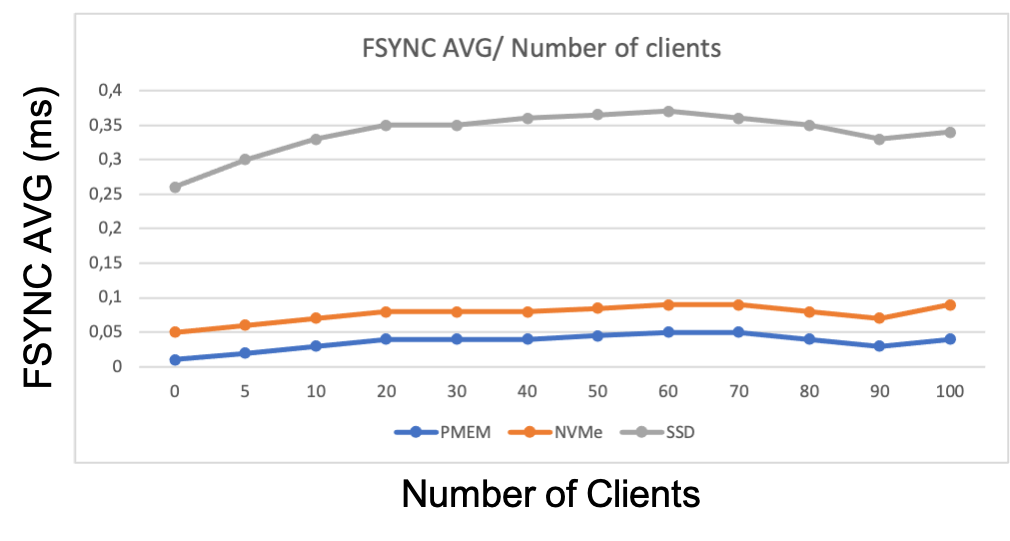
FSYNC AVG/ Number of clients
As recommended in the etcd documentation I monitored the backend_commit_duration_seconds and wal_fsync_duration_seconds parameters to verify that disk I/O was working as expected.
The results show that the different storages perform as expected, with the SSD being the slowest, the NVMe much faster and the PMEM even faster. The SSD showed fsync times of less than 0.5 ms (the etcd documentation suggests that the fsync time should be less than 10 ms). We can conclude that all tested storage options meet the need for etcd well, including the SSD.
 Conclusion
Conclusion
Faster storage did not improve node performance, and it is likely that network latency would limit performance even if faster storage worked. I also looked at network I/O but no bottlenecks were found, network throughput decreases as the load increases.
So we can conclude that etcd does not take advantage of the persistent memory features ,I recommend the Intel® Optane™ persistent memory for other applications that benefit from its higher bandwidth and lower latency.
etcd is written in Go, with the go-pmem project, a project that adds native persistent memory support to Go maybe a new version etcd will allow to take better advantage of PMEMs features ….
For the moment an SSD is sufficient to get good performance out of your etcd cluster, and NVMe is probably reasonable if you want to be sure that storage is not a bottleneck.
 Resources
Resources